 Ed's Big Plans
Ed's Big PlansNeural Grammar Network
The NGN is a feed-forward back-propagation artificial neural network that classifies formal strings based on a parse tree defined by a formal grammar in Greibach Normal Form. The NGN takes on the structure of a parse tree, such that node layers (activations) are mapped onto language symbols and weight layers are mapped onto the edges that connect these symbols. Because the syntax of the strings to classify (or curve fit) are specified in GNF, it is possible to nest strings within strings to form recursive structures. The activity of syntactic recursion maps thus to a recursive structuring of the NGN. The NGN was originally designed to work with SMILES and InChI to classify and curve-fit bioactive molecules. I’d be very interested if you happened to uncover another problem domain to which the NGN may be amenable.
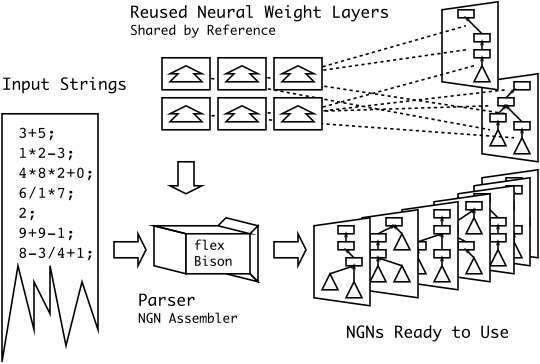
The NGN internally uses flex and Bison to build up the network graph. Weight layers are re-used — this re-use enables the persistant memory between training parses and recognition parses.
>>> Download: ngn_generator.tgz | Slideshow: Neural Grammar Networks in QSAR Chemistry (BIBM09) <<<
Warning: This code is very ad hoc as most of it was written while I was learning Python/flex/bison — contact me if there is anything you want explained / rewritten / refactored for your project.
Readme File.
= The Neural Grammar Network (NGN) =
version: 0.90
date : 2012-01-12
license: Creative Commons Attribution 3.0 Unported
http://creativecommons.org/licenses/by/3.0/
author : Eddie Yee-Tak Ma
e-mail : ed.yt.ma@gmail.com
web : https://eddiema.ca
note : The file "ngn_generator/grammars/smiles.bnf" is in the public domain
= Contents =
(1) What's a Neural Grammar Network (NGN)?
(2) System requirements
(3) Building an NGN using one of the included grammars
(4) Building an NGN for a target formal language
(5) Citing the NGN
(6) References
= (1) What's a Neural Grammar Network (NGN)? =
The Neural Grammar Network is a neural network that is structured along the
parse tree of a formal language. The internal symbols of the parse are mapped
to the node layers of a feed-forward network. These node layers are the
activation values of the network. The edges of the parse are mapped to the
weight layers. While the node layers are only needed to pass an activation
value forward, the weight layers represent the training of the network and can
be saved and loaded in order to perform training and recognition tasks.
The NGN was originally used for Quantitative Structure-Activity Relationship
chemistry problems, where molecules were matched against some biological
activity given the formal languages SMILES[1] and InChI[2]. An implementation
of each grammar is included in the directory "ngn_generator/grammars" (the most
recent compatible data was run in 2009; InChI v1.00).
= (2) System requirements =
To build an NGN binary, you will need the following software on your system:
* Python 2.3
* flex 2.5.x or an equivalent lex
* bison (GNU Bison) 2.3 or an equivalent yacc
* gcc 4.x
* make (GNU Make) 3.x
= (3) Building an NGN using one of the included grammars =
To build an NGN to recognize InChI, run "main.py" as follows:
"""
python main.py grammars/inchi.bnf inchi
make -C inchi
"""
This will create a binary 'ngn_generator/inchi/inchi'.
The NGN binary can explain its arguments with the '-h' parameter as in:
"""
./inchi/inchi -h
"""
In order to train an NGN, you need to have pairs of files available; one to
hold the formal language strings and the other to hold response values. I've
included an example pair in "ngn_generator/example_data" as follows:
"ngn_gnerator/example_data/example_inchi.txt"
Example formal language strings (InChI v1.00)
"ngn_gnerator/example_data/example_value"
Example response value file:
The first eight molecules are returned with the search term 'steroid' in
PubChem[3] by ascending molecular weight and the last eight molecules are
returned for 'ribose'. The value '0.8' is for the term 'steroid', and '0.2' is
for the term 'ribose'.
To perform training, do this (all one line):
"""
$ ./inchi/inchi -tdiskonce -loud example_data/example_inchi.txt
example_data/example_value.txt weights.txt
"""
Notice that a weights file has been saved as "weights.txt".
To perform recognition, do this:
"""
$ ./inchi/inchi -r -loud example_data/example_inchi.txt response.txt weights.txt
"""
Notice that the recognition responses are saved as "response.txt".
Note that in reality, you'd train on one set of data, then test on another set.
Note also that you aren't limited to binary classification; regression is also
possible.
= (4) Building an NGN for a target formal language =
If you have a different target formal language or you're finding parse errors,
you can specify your own '.bnf' file and '.nodes' file. Contact me for more
information as this process can become involved.
= (5) Citing the NGN =
If you've used the NGN in academic work, please cite:
Eddie YT Ma, Christopher JF Cameron, Stefan C Kremer,
Classifying and scoring of molecules with the NGN: new datasets, significance
tests, and generalization. BMC Bioinformatics 2010, 11(Suppl 8):S4.
http://dx.doi.org/10.1186/1471-2105-11-S8-S4
= (6) References =
[1] Craig A James, OpenSMILES Specification (DRAFT: 2007-11-13),
http://www.opensmiles.org/spec/open-smiles.html
(Retrieved 2012-01-12)
[2] The IUPAC International Chemical Identifier,
http://old.iupac.org/inchi/download/index.html
(Retrieved 2012-01-12)
[3] The PubChem Project,
http://pubchem.ncbi.nlm.nih.gov/
(Retrieved 2012-01-12)
References.
Eddie YT Ma, Christopher JF Cameron, Stefan C Kremer (October 2010) Classifying and scoring of molecules with the NGN: new datasets, significance tests, and generalization. BMC Bioinformatics 2010, 11(Suppl 8):S4 (MSc work). http://dx.doi.org/10.1186/1471-2105-11-S8-S4
