 Ed's Big Plans
Ed's Big PlansArchive for the ‘Biochemistry’ Category
Virus capsids are pretty
Brief: The majority of virus protein coats (capsids) are in the shape of an icosahedron — a figure with twenty equilateral triangles. The first time I saw this rendered was in a paper by David S. Goodsell. In it, Goodsell describes proteins with structural symmetries. Four viruses are used as examples — they are tobacco necrosis virus (2BUK), tomato bushy stunt virus (2TBV), bluetongue virus (3IYK) and simian virus 40 (1SVA) linked here to their RSCB PDB entries.
Pretty, aren’t they? Very pretty.
If you follow the PDB links, you can take a look at how a single tessellation unit appears, how long a chain is and how massive the capsid is.
Notice: The icosahedron (twenty equilateral triangles) must not be confused with the dodecahedron (twenty points).
Protein Project Progress…
Last week, Liz, Aron, Andrew, Brendan and I sat down to discuss the beta-trefoil project. It was a good chance for me to understand the methods used and the kinds of results we are interested in for my own TIM Barrel project.
Continuing on with the structural repeat problem, I’ll today be writing a short FSA parser that can handle DSSP or DSS output– simply, a very primitive machine will be used to imitate a human’s visual inspection of repeated secondary structural elements in given proteins. This is in line with the work I did manually staring at structures to get a grasp of how to look at protein models, and also in line with the objective to automate much of this work. Prior to that step, I reduced the probability of doing redundant work by using BLASTCLUST and selecting only a few known structures in each cluster to inspect… a sequence based alignment for each cluster will inform me of where my manually detected repeat boundaries map to the remaining sequences.
Oddity: If you BLASTCLUST all the “FULL” (not “SEED”) sets of TIM Barrel sequences for the entire fold from PFAM along with the sequences of known TIM Barrel fold structures of SCOP, you’ll find that cluster fifteen (as of today) has these elements:
1YBE_A A6U5X9 A6WV52 Q2KDT0 Q2YNV6 Q6G0X7 Q6G5H6 Q8UIS9 Q8YEP2 Q92S49 Q98D24 A1UUA2
In the above listing, 1YBE:A (PDB code) is the sole known PDB structure, while the remainder are putative TIM Barrels (uniprot codes) as determined by the HMM model from PFAM.
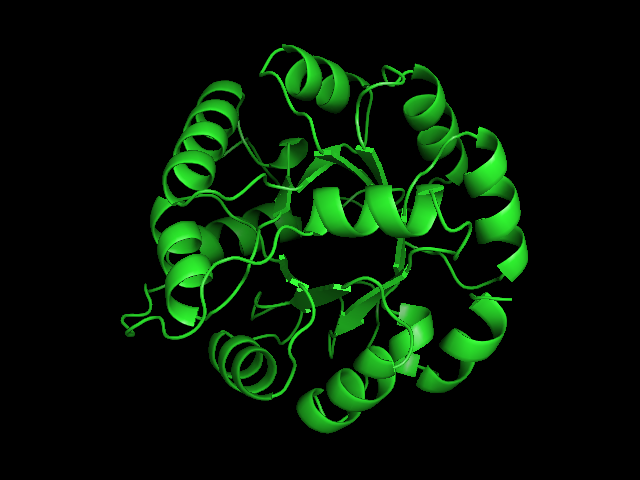
The enzyme 1YBE looks like this…
It’s an oddity because of the number of alpha-helices inserted within what is usually a hydrophobic beta barrel– the red pieces of ribbon should form a hollow cylinder, but it’s split apart for 1YBE and accommodates a bunch of cyan helices. Labeled in white are helices that break with the beta-alpha repeating secondary structural element (SSE) pattern by occurring before the first repeat. Labeled in green are breaks between beta-alpha SSE patterns.
Reference
Seetharaman, J., Swaminathan, S., Crystal Structure of a Nicotinate phosphoribosyltransferase [To be Published]
Squishy TIM Barrel Subunits
Again with the TIM Barrel pictures! Here’s some text about it from my notes…
1a5m (A Urease) is a really interesting protein– it consists of three subunits. Each subunit consists of three unique domains: a very squashed TIM Barrel, an alpha-alpha-alpha-beta-beta domain and a beta-beta-alpha-beta-beta domain. I’m not yet sure what to call little broken alpha helices that have less than two complete turns. The TIM Barrel (though exceedingly asymmetrical) will still be accounted for in the data to be analyzed. The TIM Barrel (566 amino acids) is the alpha subunit of each symmetrical subunit. The remaining two domains are the alpha and beta subunit though PDB is not clear which is which: they each weigh in at 100 and 101 amino acids. 1a5m is part of several solved urease structures in the PDB– the collection: {1A5K, 1A5L, 1A5M, 1A5N, 1A5O} are solved by Pearson et al. (1998).
References
Matthew A. Pearson, Ruth A. Schaller, Linda Overbye Michel, P. Andrew Karplus, and, Robert P. Hausinger (1998). Chemical Rescue of Klebsiella aerogenes Urease Variants Lacking the Carbamylated-Lysine Nickel Ligand. Biochemistry. 37(17):6214-20.
Squishy squishy shapes– the giant pink object in the next picture is actually three such TIM Barrels, each of which belongs to one of the three subunits.

Each of the three subunits are shown separately below…
 |
 |
 |
Aesthetically pleasing– these images were captured from the JMol output available from RCSB PDB.
TIM Barrels look like this…
It occurred to me that I didn’t actually post any images in the past few posts. Here are two TIM Barrels that I’ve arbitrarily picked from DATE. Note– the image files are horribly misnamed, so please use the text description underneath.

From left to right– these figures are 1A53 (Beta Strand C-Face), 1A53 (Beta Strand N-Face), 1BG4 (Beta Strand N-Face), 1BG4 (Beta Strand C-Face). 1A53 is called “indole-3-glycerol phosphate synthase” and 1BG4 is called “xylanase” isolated from Penicillium simplicissimum. I won’t go into the function of each of these enzymes, but they do illustrate what a general beta-alpha TIM barrel looks like. TIM Barrels comprise of eight beta-alpha secondary structure elements. Extra helices and sheets may occur but must flank the TIM Barrel-like portion of the protein domain (1A53 has a very prominent extra alpha helix close to the camera in the far left image). The “barrel” name derives from the twisted cylinder enclosed by the parallel beta sheets in the middle of the object. TIM barrels can be deformed quite a bit too if they’re a subunit part of a larger holoprotein.
The four-character designations (1A53, 1BG4) are RCSB (A Resource for Studying Biological Macromolecules) Protein Data Bank identifiers– I’ve found that SCOP frequently links into PDB while PFAM frequently links to UniProtKB (Knowledge Base) and utilizes UniprotKB identifiers. More on that later…
TIM Barrels and 4-Alpha Helix Bundles
Beta-Alpha TIM Barrels and 4-Alpha Helix bundles are the first of the major folds I’ll be looking at here at Waterloo…
As with all academic projects, the probability of goal, approach and method mutation is high. Looking at the above protein folds serves as an excellent starting point as I’ll be applying some of the established methods that Andrew and Aaron have developed.
Alpha helices and Beta sheets are objects that any highschool biologist is acquainted with. To recapitulate, alpha helices are sequences of amino acids arranged so that the alpha carbon of each amino acid falls along the path of a helix. The number of amino acids per turn in this peptide and the regularity of the helix are determined by both the sequence and the environment that peptide finds itself in. Amino acids in the beta sheet conformation are arranged so that their alpha carbons zig zag. The result is a nice wide and flat shape schematically drawn as a sheet. Alpha helices and Beta sheets are collectively called secondary structural elements.
So, folds are these giant overarching classification of proteins– Folds themselves are inherently structural, so classifying them OR using them as classifications is only relevant in structural studies and databases on the web like SCOP and CATH. In databases such as SCOP and CATH, classification of similarly structured proteins start by determining whether the protein contains mostly alpha helices; mostly beta sheets; beta sheet and alpha helices alternatively and irregularly; or beta sheet and alpha helices in distinct regions of a protein. In SCOP, further classification is done by manually assigning proteins to smaller and smaller categories, while in CATH, these classifications are done by a hidden Markov model and then manually inspected (or not). It turns out that CATH uses a similar manual approach, and uses HMMs only to assist; contrast with PFAM which actually utilizes HMMs for the majority of work and is verified afterward by humans.
Certain folds like the beta-Trefoil and TIM Barrel benefit from containing only proteins that cleanly fit into some subcategory or several subcategories– it is then possible to just drill into the right level of categorization and pull out all of the beta-Trefoils and TIM Barrels we want.
The 4-Alpha-Helix Bundle constitutes a fold of protein that manages to be spread around the databases, being a very common secondary structural repeat; also a very small repeat when compared to the two giants above. These two items represent an interesting contrast too. Both machine and human intelligence pulls TIM Barrels together while sprinkling alpha-helix bundles across databases and subcategories. And yes, the size difference helps too.
So, I’m starting with a structural then sequence based alignment for single domain TIM Barrels and alpha-helix bundles; to be completely focused, an objective is named: To identify where sequence repeats occur in each individual protein.
